#install.packages("tidyverse")
library(tidyverse)
var_labels <- read.csv("code/kap2_data_desc.csv")
df <- read.csv("code/kap2_data.csv")
#view(var_labels)
Handelsteori
Gravitationsmodellen
Dataøvelse

I vores gennemgang af gravitationsmodellen i kapitel 2, så vi på hvordan både økonomisk størrelse (BNP) og afstand mellem lande påvirker handelsstrømme.
\[ \text{handel}_{ij} = A \cdot \frac{\text{BNP}_i^{\beta_1} \cdot \text{BNP}_j^{\beta_2}}{\text{afstand}_{ij}^{\beta_3}} \]
Som vi også så, kan modellen log-transformeres til en lineær form, som kan estimeres ved hjælp af OLS regression:
\[ \begin{aligned} \ln(\text{handel}_{ij}) &= \ln(A) \\ &+ \beta_1 \cdot \ln(\text{BNP}_i) \\ &+ \beta_2 \cdot \ln(\text{BNP}_j) \\ &+ \beta_3 \cdot \ln(\text{afstand}_{ij}) \\ &+ \varepsilon_{ij} \end{aligned} \]
I denne øvelse skal vi arbejde med et datasæt over international handel, og estimere gravitationsmodellen ved hjælp af regressionsanalyse i R.
Kom i gang!
Til at begynde med, skal vi loade vores data. - kap2_data.csv indeholder selve datasættet - kap2_data_desc.csv giver en oversigt over variablerne i datasættet.
Jeg anbefaler at man bruger pakken tidyverse, som gør datahåndtering og visualisering lettere i R. tidyverse er en samling af flere forskellige pakker, herunder dplyr og ggplot2.
tidyverse skal først installeres med install.packages("tidyverse"), hvis du ikke allerede har den installeret. Her i koden kommenterer jeg installationen ud ved at sætte et # foran install.packages.
Jeg ‘gemmer’ de to csv filer i henholdsvis var_labels og df ved at bruge pilen <-. Man kan tildele et hviklet som helst navn: df fungerer ligeså godt som jegforstaardetikke, eller holdkaeftdetherersvaert. Men df er selvfølgelig kortere!
df står for ‘dataframe’, som er navnet på den tabel-lignende datastruktur i R.I R kan man undersøge datasættet med view() funktionen, eller ved at klikke på df i ‘Environment’ panelet i RStudio. Ellers kan man læse indholdet af var_labels her:
De relevante variabler for vores analyse er:
trade: Værdien af servicehandel (eksport) fra landexptil landimpgdp_exp: BNP for eksportlandetgdp_imp: BNP for importlandetdist: Afstand mellem de største byer i eksport- og importlandet (i km)
ForsigtigAndre variabler?
Man kunne også vælge at inkludere andre variabler som kan være med til at forklare handelsomkostninger og barrierer udover den fysiske afstand: fx fælles sprog, kolonihistorie, markedsadgang. Man kunne sågar afprøve forskellige mål for afstand.
Men i denne øvelse holder vi os til de fire ovenstående variabler.
En vigtig del af dataforberedelsen er at transformere variablerne, sådan at de kan bruges i regressionsanalysen. Som vi diskuterede i undervisningen, behøver vi at log-transformere variablerne i gravitationsmodellen for at kunne bruge OLS. Heldigivis er det let at gøre i R med dplyr pakken (som er en del af tidyverse).
- Vi bruger
select()til at vælge de relevante variabler (og dropper resten). - Vi bruger
filter()til at fjerne observationer hvortradeer 0, eller hvor der er observationer med manglende værdier for en eller flere af de uafhængige variabler. (Manglende værdier kan vælges medis.na(), og!foran betyder ‘ikke’.) - Vi bruger
mutate()til at log-transformere hver af de fire variabler.
df <- df %>%
select(trade, gdp_exp, gdp_imp, dist) %>%
filter(trade > 0) %>%
filter(!is.na(gdp_imp) & !is.na(gdp_exp) & !is.na(dist)) %>%
mutate(
trade = log(trade),
gdp_exp = log(gdp_exp),
gdp_imp = log(gdp_imp),
dist = log(dist)
)
ForsigtigHvorfor
df <- df %>%?
Logikken med koden ovenfor er at vi definerer df <- som den oprindelige df, som så bliver ‘piped’ (%>%) igennem en række funktioner (select(), filter(), mutate()). Resultatet af alle disse funktioner bliver så gemt tilbage i df. Det er en meget almindelig måde at arbejde med data i R.
Man kunne også have valgt at bruge df til at skabe en ny dataframe, fx df2 <- df %>%. Men da vi ikke skal bruge den oprindelige df senere i øvelsen, kan vi lige så godt overskrive den.
Nu er datasættet klar til analyse!
Korrelationer
Den første del af opgaven er at undersøge korrelationerne mellem variablerne i datasættet. Dette kan gøres med cor() funktionen i R. Vi kan også lave nogle simple scatter plots med ggplot2 pakken (også en del af tidyverse).
Man kan bruge dataframen df til at lave korrelationsmatrixen. Det kræver dog, at vi først konverterer df til en matrix med as.matrix() funktionen, og derefter kan vi bruge cor() funktionen. Man kan printe resultatet direkte i konsollen ved at kalde korrelationer (eller hvad man ellers har kaldt objektet).
korrelationer <- df %>%
as.matrix() %>%
cor()
korrelationer trade gdp_exp gdp_imp dist
trade 1.0000000 0.36433095 0.37306853 -0.26478585
gdp_exp 0.3643309 1.00000000 -0.31031405 0.05176184
gdp_imp 0.3730685 -0.31031405 1.00000000 0.04309818
dist -0.2647858 0.05176184 0.04309818 1.00000000Tabel 2 viser korrelationerne i en lidt pænere tabel.
Dernæst kan man lave nogle simple scatter plots for at visualisere sammenhængene mellem variablerne. Herunder har jeg lavet to plots ved hjælp af ggplot2 pakken: et for BNP og handel, og et for afstand og handel.
- Scatter plottene laves med
geom_point(). - Jeg har tilføjet en lineær regressionslinje med
geom_smooth(method = lm). - Til at gøre plottene nemmere at forstå, har jeg ændret aksetitlerne med
labs(), og brugt et minimalistisk tema medtheme_minimal().
AdvarselObs!
Jeg har selv defineret farverne i mine plots: dvs. blue, green og red er variabler. Hvis man bare kopierer koden her, vil man støde på en fejl. Man kan bruge standardfarverne i ggplot2 ved at fjerne colour = blue osv., eller vælger allerede definerede farver som fx colour = "blue" (bemærk anførselstegnene!). For at se listen over tilgængelige farver, kør colours() i R-konsollen.
## Farver (kan defineres frit: se `colours()` i R)
# blue <- "navyblue"
# red <- "firebrick1"
# green <- "springgreen"
plot_bnp <- ggplot(data = df, aes(x = gdp_exp + gdp_imp, y = trade)) +
geom_point(colour = blue) +
geom_smooth(method = lm, se = FALSE, colour = green) +
labs(x = "Log(BNP eksport * BNP import)", y = "Log(Handel)") +
theme_minimal()
plot_dist <- ggplot(data = df, aes(x = dist, y = trade)) +
geom_point(colour = blue) +
geom_smooth(method = lm, se = FALSE, colour = red) +
labs(x = "Log(Afstand i km)", y = "Log(Handel)") +
theme_minimal()Ved at køre hhv. plot_bnp og plot_dist i konsollen, får man at se plots der gerne skulle ligne figur 1 og figur 2. Nedenfor viser jeg også de samme plots i en interaktiv udgave (med plotly pakken).
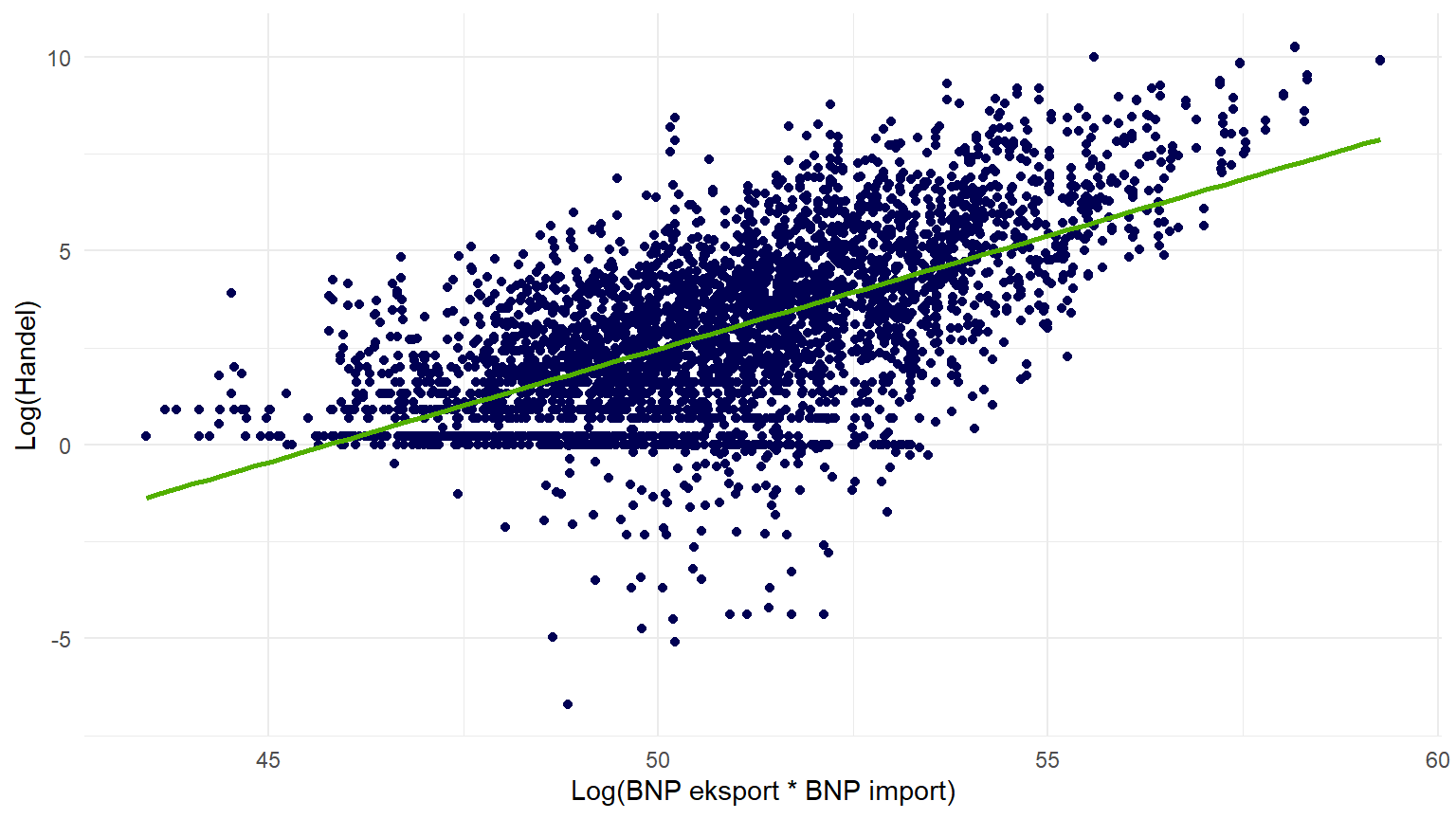
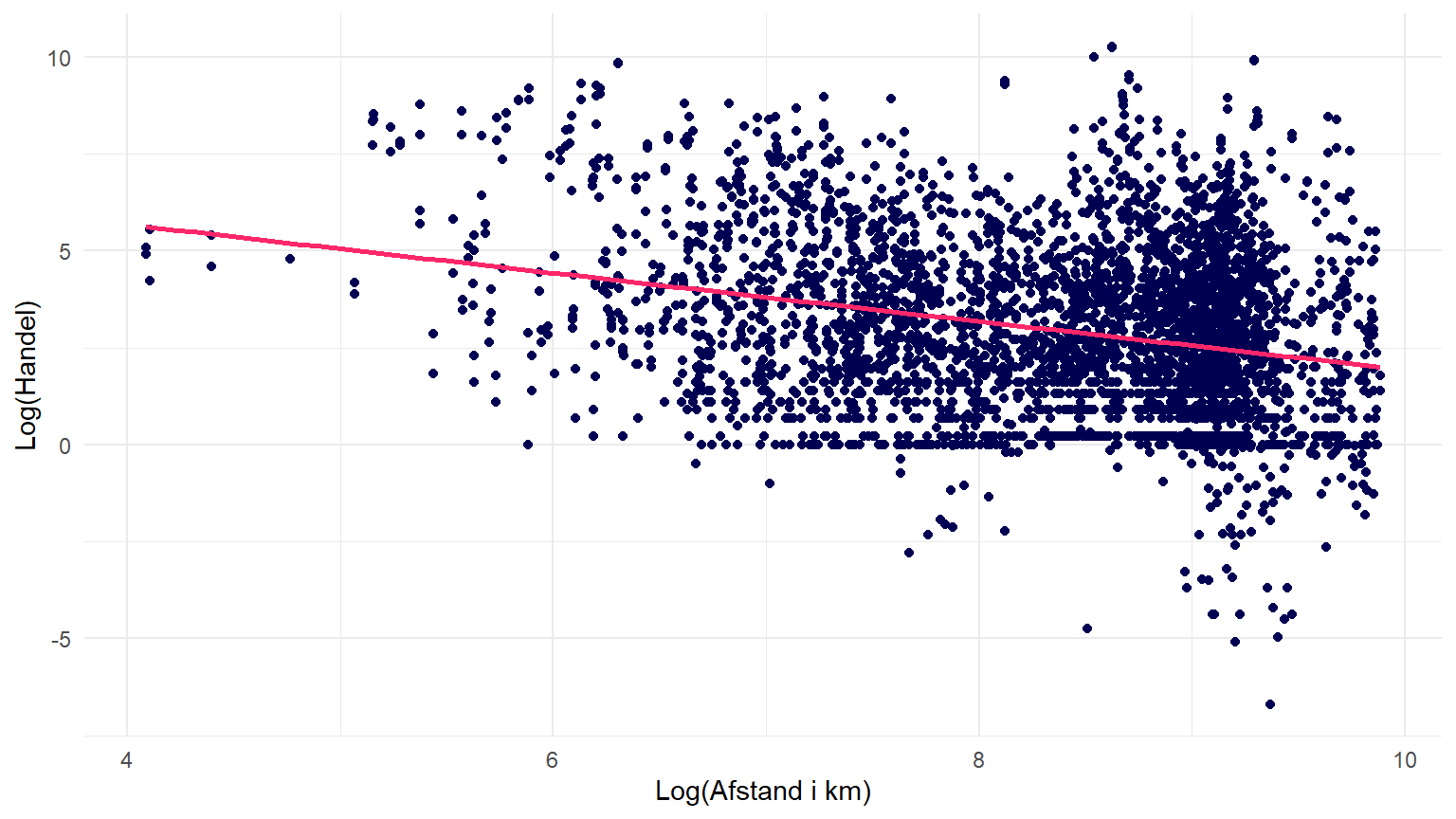
Regressionsanalyse
Udover at man kan tilføje en lineær regressionslinje i scatter plottene, kan man også estimere selve regressionsmodellen ved hjælp af lm() funktionen i R. Herunder estimerer jeg gravitationsmodellen ved hjælp af OLS. Jeg bruger summary() funktionen til at vise resultaterne i konsollen.
model_ols <- lm(trade ~ gdp_exp + gdp_imp + dist, data = df)
summary(model_ols)
Call:
lm(formula = trade ~ gdp_exp + gdp_imp + dist, data = df)
Residuals:
Min 1Q Median 3Q Max
-7.6864 -0.9680 0.0393 1.0775 5.6593
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) -21.68498 0.57010 -38.04 <2e-16 ***
gdp_exp 0.60063 0.01305 46.04 <2e-16 ***
gdp_imp 0.61491 0.01324 46.44 <2e-16 ***
dist -0.74857 0.02700 -27.73 <2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 1.607 on 3880 degrees of freedom
Multiple R-squared: 0.4944, Adjusted R-squared: 0.494
F-statistic: 1265 on 3 and 3880 DF, p-value: < 2.2e-16Det er selvfølgeligt også muligt at få en pænere tabel med resultaterne, som fx tabel 3.
Her bruger jeg gtsummary pakken. Men der findes flere muligheder for at lave formatterede tabeller som kan sættes ind i fx Word eller LaTeX dokumenter.
| Koefficient (standardfejl) | |
|---|---|
| (Intercept) | -22*** (0.570) |
| gdp_exp | 0.60*** (0.013) |
| gdp_imp | 0.61*** (0.013) |
| dist | -0.75*** (0.027) |
| No. Obs. | 3,884 |
| R² | 0.494 |
* \(p<0.05\); ** \(p<0.01\); *** \(p<0.001\).
Er man bekymret for heteroskedasticitet i residualerne, kan man også estimere modellen med robuste standardfejl ved hjælp af pakken estimatr.
#install.packages("estimatr")
library(estimatr)
model_robust <- lm_robust(trade ~ gdp_exp + gdp_imp + dist, data = df)
#summary(model_robust)Som tabel 4 viser, er resultaterne med robuste standardfejl meget lig de almindelige OLS resultater. Det vil sige, i dette tilfælde, er der ingen stor forskel på standardfejlene.
| Koefficient (standardfejl) | Koefficient (standardfejl) | |
|---|---|---|
| (Intercept) | -22*** (0.570) | -22*** (0.546) |
| gdp_exp | 0.60*** (0.013) | 0.60*** (0.012) |
| gdp_imp | 0.61*** (0.013) | 0.61*** (0.013) |
| dist | -0.75*** (0.027) | -0.75*** (0.026) |
| No. Obs. | 3,884 | 3,884 |
| R² | 0.494 | 0.494 |
* \(p<0.05\); ** \(p<0.01\); *** \(p<0.001\).
ForsigtigEr OLS den bedste metode?
Man kan altid diskutere om OLS er den bedste metode til at estimere gravitationsmodellen. Nogle argumenterer for at Poisson Pseudo-Maximum Likelihood (PPML) er bedre, især når datasættet indeholder mange observationer med 0 i handelsstrømme. I dette datasæt har vi dog allerede fjernet observationer med 0 i trade.
Læs mere
Denne øvelse er inspireret af (og bruger data fra) UNESCAP’s guide til gravitationsmodellen i international handel. Andre gode kilder inkluderer:
- Gupta, Krisna (2024). Gravity in R: a short workshop.
- Vargas, Mauricio (2023). A crash course on gravity models.
Vargas er også ansvarlig for gravity pakken, som tilbyder funktioner til estimering af gravitationsmodeller i international handel.